5 Machine Learning Breakthroughs to Accurately Categorize Text!
For the last 20 years, the survey research industry has waited with bated breath for text analysis technologies to transform the way we analyze text data. In the last year or so, technology has reached a point where they can work with a high level of accuracy.
Five key advances have made it practical for computers to automatically code text with a high level of accuracy: the prediction-based human-computer interaction model, high-quality automated predictive algorithms, universal encoders, improved analysis frameworks, and a focus on machine-understandable text.
1. The prediction-based human-computer interaction model
In the early days of artificial intelligence, the goal was to program the if-this-then-that style rules. These were known as expert systems. All the early text analysis systems in market research work the same way, with users effectively writing rules about how to categorize text data.
In the last two decades, we have recognized that part of the secret to effectively using AI is to always characterize it as a prediction problem. For example, if you're trying to translate text, rather than using dictionaries and language rules, the modern approach is to instead feed the algorithms large quantities of text that's been translated into two languages—building models that predict the text in one language based on the other.
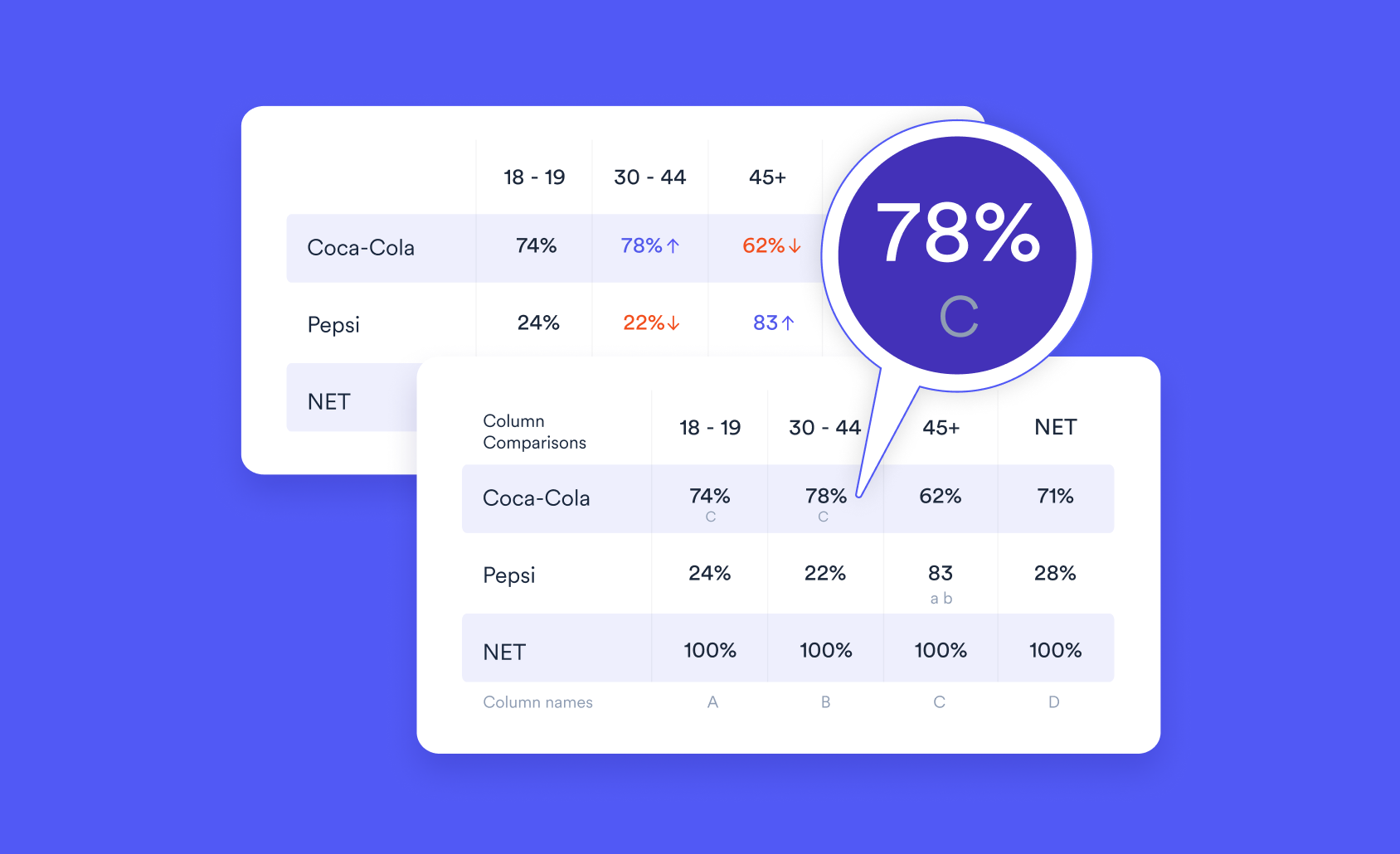
In the case of text data from survey responses, the problem is then one of figuring out the best way to get data from the user that can be predicted. One way of doing this, which is very effective, is to get a person to manually categorize (code), say, 200 responses, train a machine-learning algorithm to predict this categorization, then use it to predict the categories of all the text data not already coded. In Displayr we refer to this as Automated Text Analysis. A variant of this is to have the user manually perform categorization, then have the machine-learning systems operate in the background while making recommendations to the user. These recommendations will get more and more accurate as the user types their text.
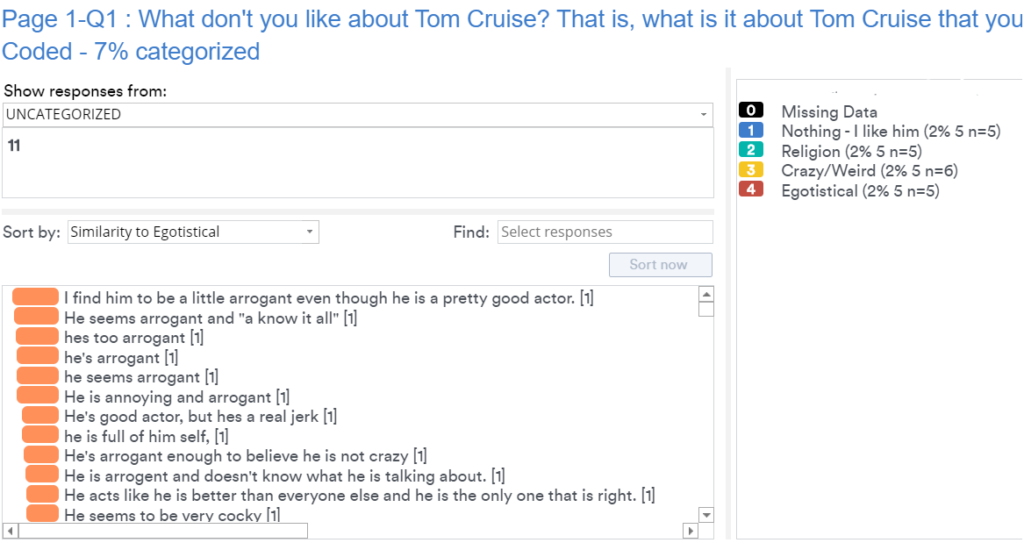
As an example, the screenshot below is from data asking people why they dislike Tom Cruise, After only coding 20 unique responses, it's possible to build a surprisingly good model. The orange bars show the likelihood that a respondent is similar to the people that have been manually categorized as being egotistical.
2. High-quality automated predictive algorithms
Twenty years ago, the best practice for predictive modeling consisted of:
- Having a highly-skilled statistician with a lot of relevant experience who understood things like heteroscedasticity, autocorrelation, interactions, transformations, family-wise error rates, basis functions, and how to address multicollinearity
- Using generalized linear models
- Careful selection of appropriate predictors
However, the second key breakthrough has been that the development of fully-automated predictive models that, when left on their own do a better job than the most skilled statistician with a generalized linear model. The most well-known example of this is the deep learning algorithms that capture the attention of the media, but for most of the types of problems faced by market researchers, random forest and xgboost usually work better.
3. Improved encoders
A predictive algorithm is only as good as the predictor variables, which is where the most recent innovations have occurred. Encoding refers to converting the text data into numbers.
Document-term-matrix
The first important encoding tool of text data was the document-term-matrix, which creates a variable for each term (word or phrase) that appears in each text response (each text response is referred to as a document in Text Analysis literature). The early years of text analysis consisted of a whole host of improvements in the creation of document-term-matrices, such as dealing with spelling mistakes, synonyms, and the detection of phrases (n-grams, to use the jargon).
The example below shows a document-term-matrix for reasons for disliking Tom Cruise.
Sentiment analysis
The next level of improvements in encoding consisted of attempting to extract meaning from text data, rather than just common words. In market research, this is most commonly associated with sentiment analysis, as shown in the example below.
Entity extraction
More sophisticated approaches to extracting sentiment from text data do so by attempting to understand the structure of the language (e.g., identify nouns, verbs, etc.). One useful application of this approach is entity extraction.
Word embeddings
The next key innovation was Word embeddings. A word embedding represents a word by a set of coordinates (numbers). The two-dimensional embedding of the terms from the document-term-matrix above is shown below. Typically these are created using neural networks.
Sentence embeddings
And then the final step, which was only cracked in the past few years (by the good folk at Google), was sentence encoding, where whole sentences are assigned coordinates.
4. Better analysis frameworks
In the early days, text analysis was viewed as technique, just like, say, cluster analysis or conjoint. Many weird and wonderful visualizations were developed as a part of this approach. But, what's become much clearer in recent times is that this is the wrong way to think about text analysis. The better way to think about it is as a processing stage, which involves encoding text data as numbers. These numbers are just analyzed in the normal way, using standard (or awesome new) quant analysis tools.
The main implication of this for market research is a simple one: rather than attempting to create special-purpose word analyses, the goal is generally instead to use machine learning to replicate traditional coding, which is then analyzed using crosstabs.
Ready to analyze your text?
Start a free trial of Displayr.
5. Using machine-understandable text
The last breakthrough relates to making sure that the text data being analyzed can be understood by a machine. This one sounds really obvious when described, but it is quite profound in its implications.
There are two things we can do to ensure that we analyze data that is appropriate for text analysis tools:
- Ask machine-understandable questions
- Filtering data to make it consistent
Asking machine-understandable questions
Traditionally, open-ended questions have been written in a very broad way to avoid inadvertently restricting the type of data provided. For example, after asking people to rate how likely they are to recommend a company, the traditional follow up is something like "Why did you say that?". In the world of qualitative research that's not such a bad question. But, in the world of text analysis, it is horrible. Let's say somebody says "price." You can't interpret the data without knowing their response to the earlier question, and this information is typically not included in the text analysis.
If you know you are going to use automatic methods for text analysis, a much better approach is to split the question into two parts, such as "What do you like about your phone provider?" and "What do you dislike about your phone provider? ".
Or better yet, "Please list everything you like about your phone company" and providing the respondent with multiple separate boxes to enter their data into, so that you can more readily tease out differences between the responses. The more structure and the more effort put into ensuring that the responses are comparable, the better the job a computer will do in summarizing the data.
Filtering data to make it consistent
Consider data from a concept test, where you've asked people why they like each concept for 20 concepts, and the responses are all stored in a single text variable. The obvious thing to do is to attempt to perform text analysis on this variable. This can work, but only if there are consistent themes across all of the concepts. If the concepts and the types of answers given are very different, neither human nor machine will be able to extract themes. The fix is to instead perform the analysis for each concept separately (of course, you'd still want to try and do them all at once first up, as maybe they do have common themes).
The outcome
The outcome of these five innovations is that it is now possible to automatically code text data. As each of these innovations continue to mature and improve, the capabilities of text analysis will only increase. See how you can leverage more insights from your text in Displayr.
Want to try it yourself? Start a free trial.